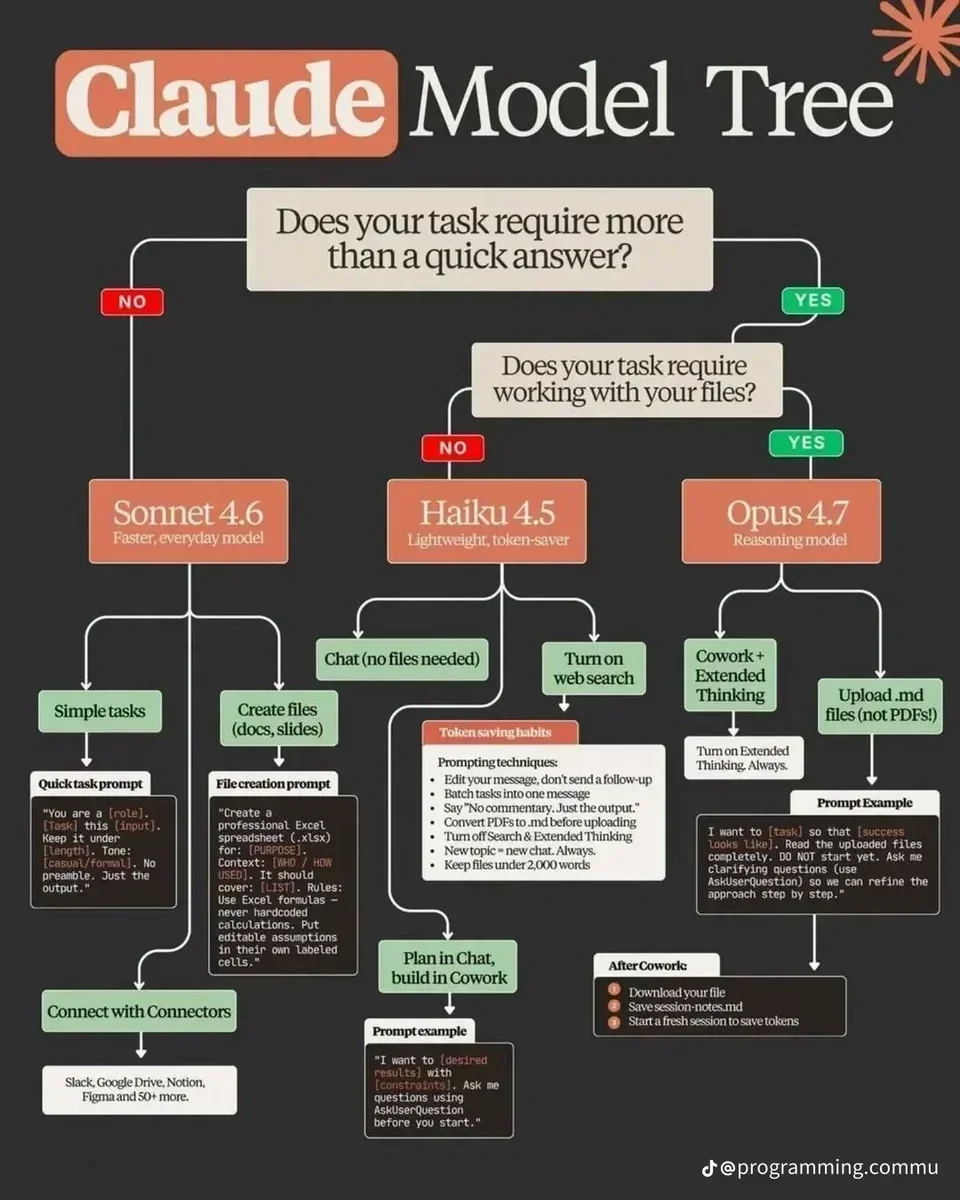
useful routes to consider for when using any llm models, claude code is one of my favs but just lately the opencode/kimi-2-5-turbo combination has really been working for me, I’m burning through tokens thou so I need to tune that up a little think. gotta done a way to scale! local maybe? overnight!